Hi I’m Jude Gomila.
I like to build and back iconic companies.
I’ve backed many unicorns from seed rounds and sometimes first check: Gusto, ClearTax, Boom, Benchling, Ginkgo Bioworks, Airtable, Carta, Ironclad, Superhuman, Mercury, Linear, Calm, Relativity Space, Astranis, Solugen, Human Interest, Stoke Aerospace + many others. Check out investing related information here.
Previously I built and sold two venture backed startups and was accepted into Y Combinator in 2008:

CEO and Founder of Golden (acq by Comply Advantage 2024). Backed by a16z, Founders Fund, DCVC, Giga Fund and others.
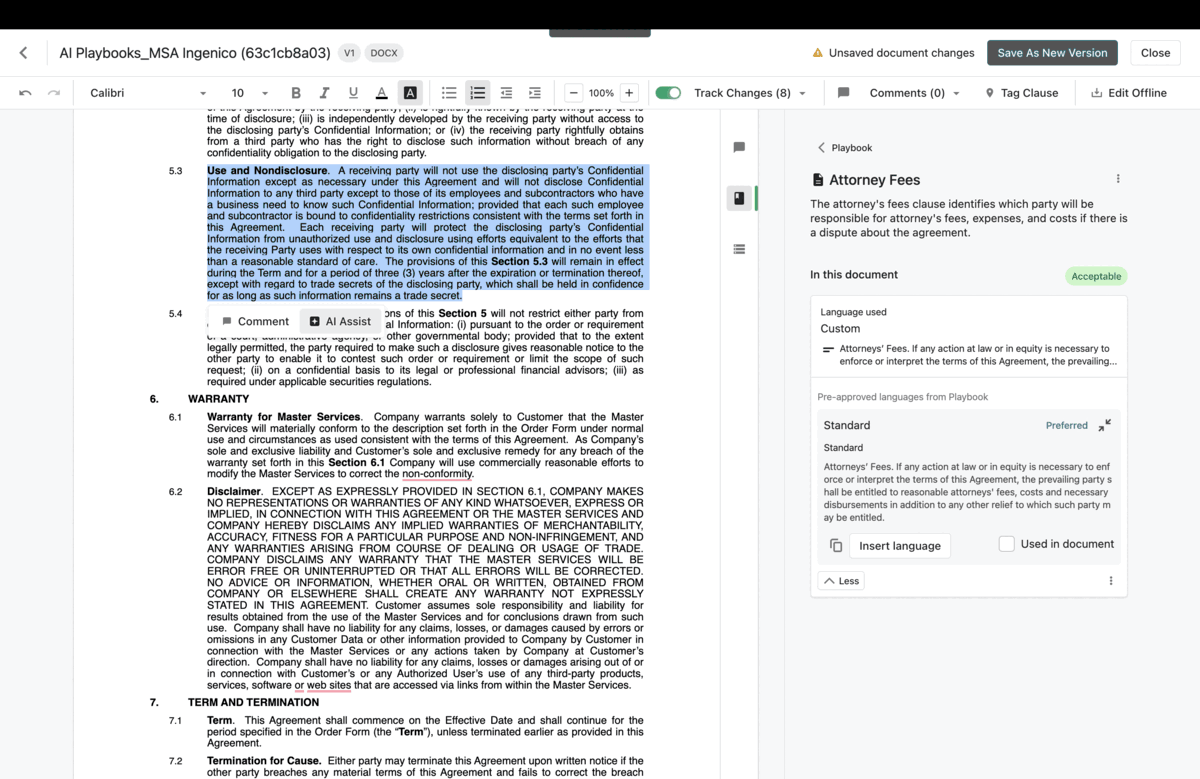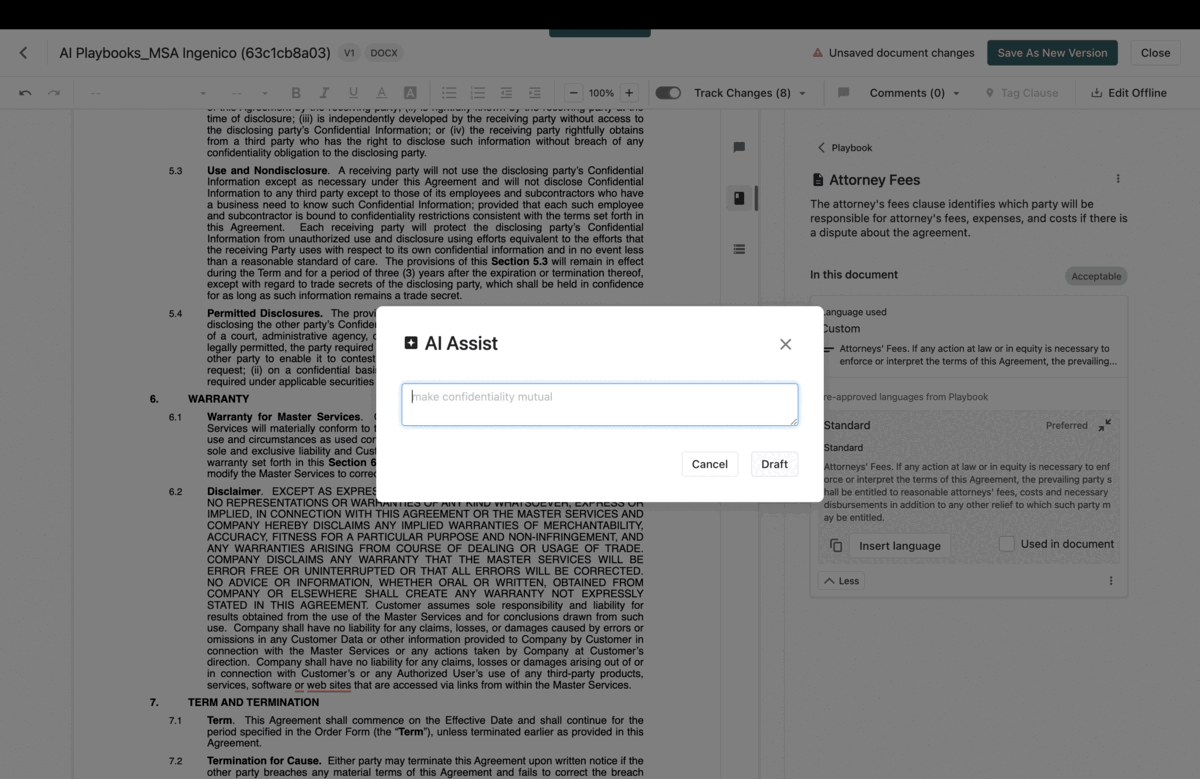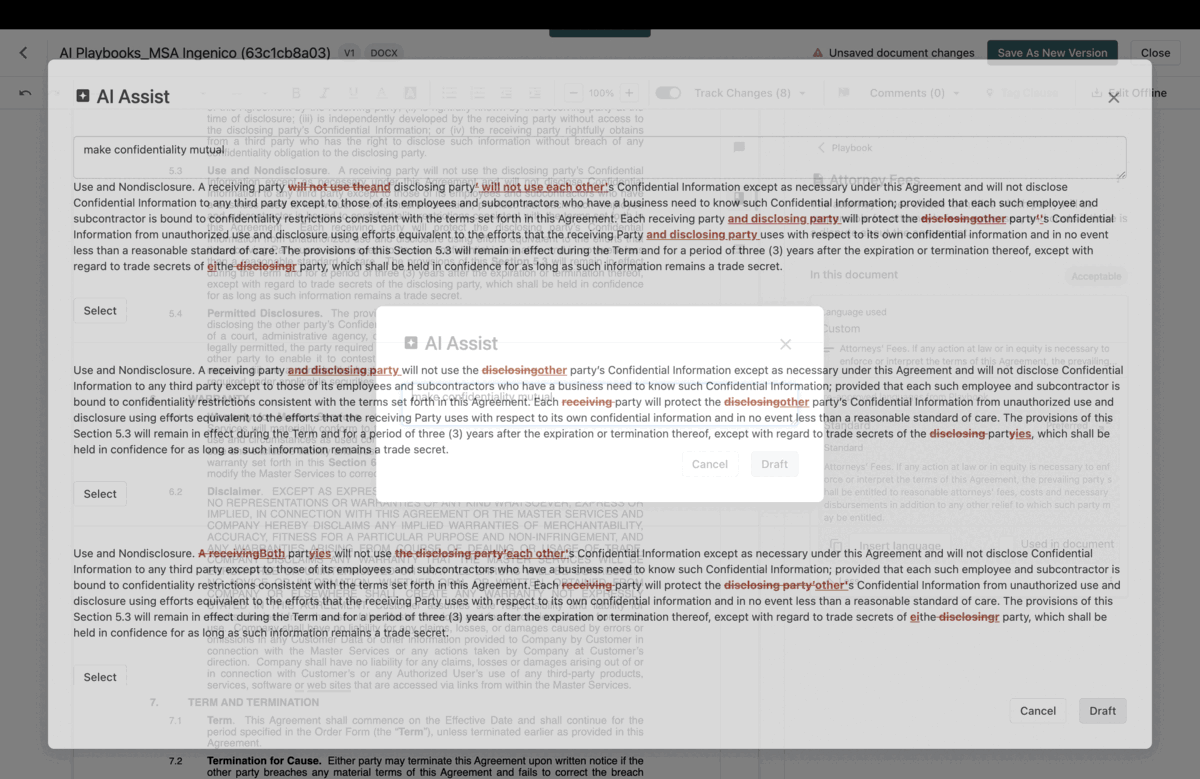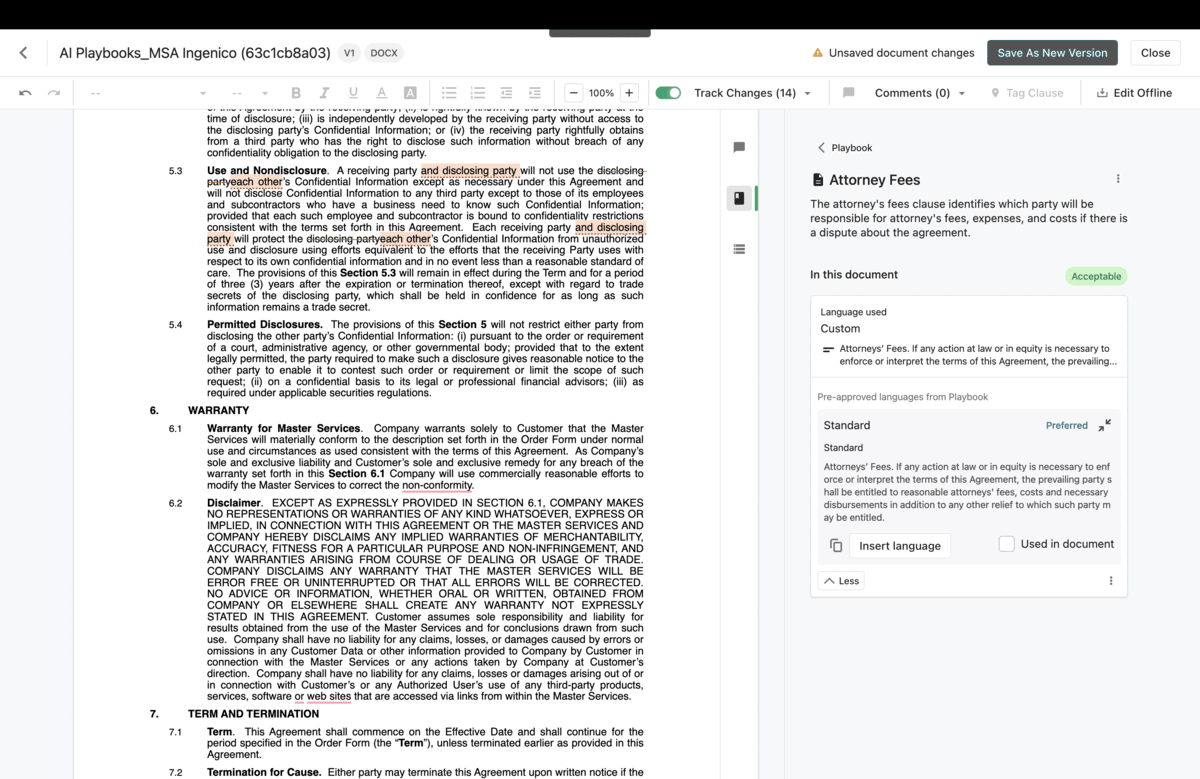
Cofounded Heyzap acquired by public company 2016.
I studied engineering at University of Cambridge attending Gonville and Caius College.
Twitter: @judegomila
Linkedin: /judegomila